Integrating VMware Code Stream and Packer
Not content to build vSphere templates periodically, this introduction shows how VMware Code Stream and Packer can be combined to trigger builds from Git updates.


Looking back a couple of months ago at some of my early endeavours with HashiCorp Packer, I'm very pleased with how things are looking now. I took Grant Orchard's advice and started using environment variables and I explored a few options for automating my template builds.
As I mentioned in my final Packer series post, I wanted to implement triggered template builds using VMware Code Stream. Whilst it's not totally finished yet - I could do with a feature adding to the vsphere-iso builder in Packer (kudos to my colleague Robert Jensen for logging it already) - it is very much functional and in use.
Because the repository for my Packer templates started life in GitHub where it isn't affected by changes or unavailability in my homelab, I thought I'd keep it there and try to use webhooks to trigger the build process in my homelab's vRA instance. Of course, GitHub webhooks can't be used directly as my vRA isn't publicly reachable from the internet. So I needed another mechanism, this one relies on:
- vRealize Automation 8.1
- vSphere
- GitHub
- GitLab Enterprise
- Docker
- DockerHub
- HashiCorp Packer
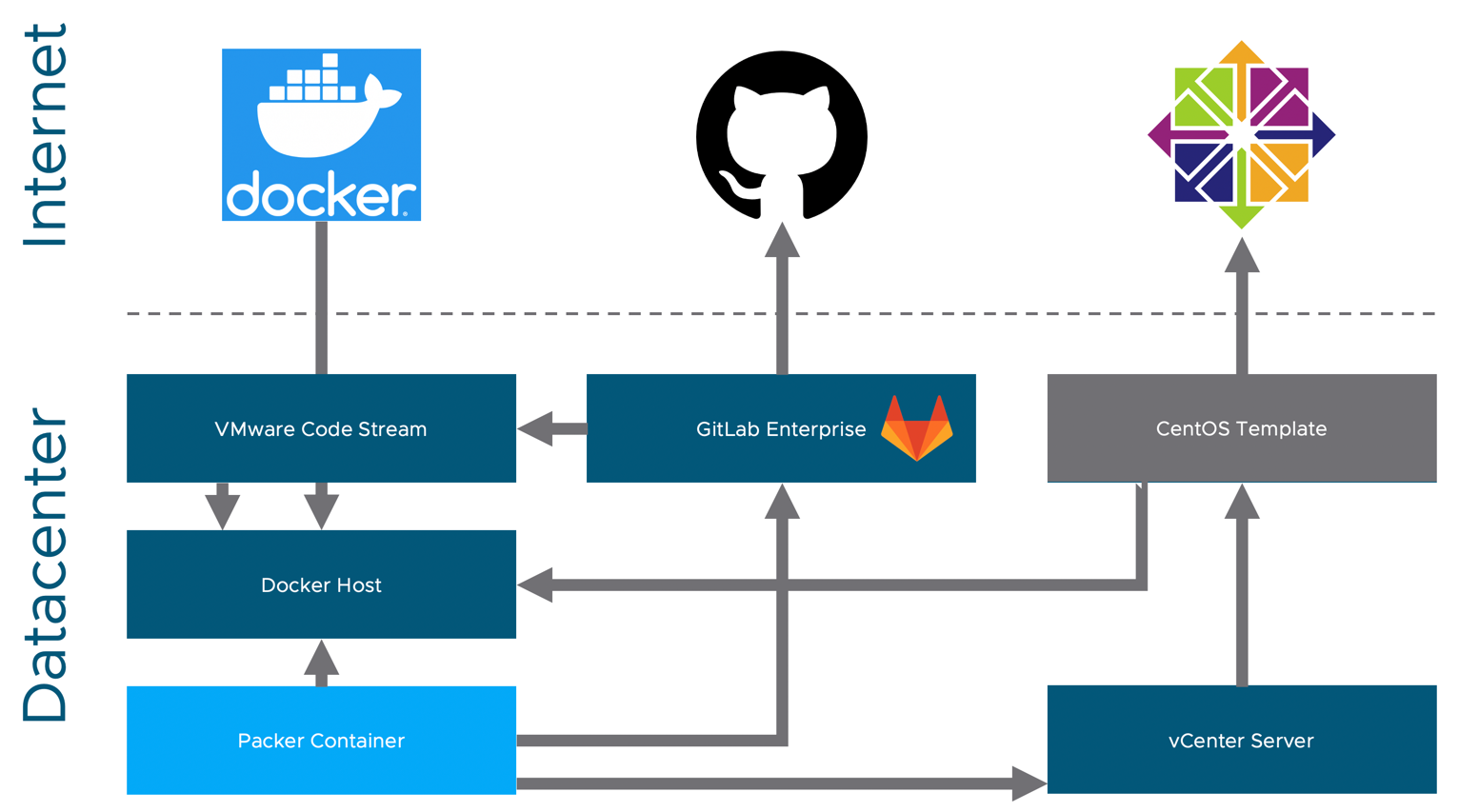
The solution that I've come up with does involve an extra couple of pieces but it also has some advantages:
- The Packer template, kickstart config and scripts in GitHub are completely devoid of any secure information (passwords, unique usernames, licenses etc) so they can be shared and hosted publicly without exposing too much vital information.
- If I blow up my lab, all of those files are still out there because GitHub holds the master copy so it's very easy to get them back again.
- At least for my Linux builds (example CentOS 8) I don't have to make floppy images, pull kickstart files directly from public locations etc. The secure stuff is all "in-house".
Most importantly, it works if you don't have your own vRA Cloud instance and host vRA in your own datacenter.
In contrast to my previous series of posts, this time I wanted to show something working and then go back and run through the bits and pieces that make it work. So I produced this video, which explains the process and then goes in to a demonstration of how it all works.
In the coming weeks I'll go in to some more detail about the individual pieces and parts. Perhaps with a few more videos as well!