Custom Naming in vRealize Automation 8.x (Pt. 1)
vRA 8.x offers several built-in mechanisms for naming workloads. This article covers them briefly and starts the process to go fully custom.


I've been a user and proponent of vRealize Automation (vRA) for quite a few years now. I think it's fair to say that there's a bit of a transition underway at the moment. There are a lot of customers on vRA 7.x and a growing number on vRA 8.x. My day job means that I have to stay current on both as I work with customers on both major versions. And my homelab reflects that position. I have both vRA 7.x and vRA 8.x deployments running. Given that all of these can provision to the same endpoints (I have limited resources), managing hostnames can get... interesting.
Last week Mark Brookfield shared his solution for hostnaming that he uses with vRA 7.x in his lab. He ran me through it on a zoom session and I was able to adopt it for my 7.x deployments. I wanted to take it a little further though and find a solution that would work both for vRA 7.x and vRA 8.x. My quick solution is what you'll find documented below.
First though I ought to touch on my lab's naming convention and the standard functionality that's available to manage naming.
Naming Convention
Like Mark, I have a naming convention in place in my lab. There aren't as many elements to it but as I refer to these elements later I need to document them briefly.
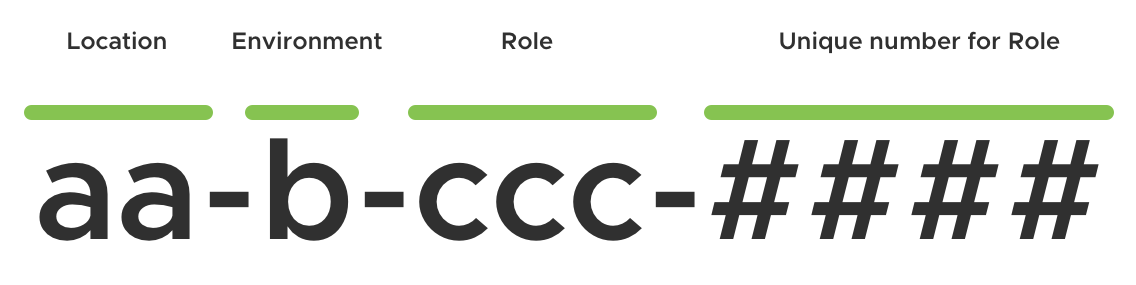
Location - Two letters that denote the country (e.g. "uk"). As I only have a single location this is pretty fixed.
Environment - A single letter that denotes the environment. The possible options are "p", "s" or "d" for "production", "staging" and "development" respectively.
Role - Three letters that indicate the core purpose of the workload. So, "esx" for my ESXi hosts, "adc" for my Active Directory servers etc.
Number - A four digit number that increments from 1. The combination of Role and Number must be unique.
Standard vRA Naming Functionality
vRA 7.x
In vRA 7.x there are Machine Prefixes that can be configured and consumed. I won't re-hash all of the product documentation for them here, but these prefixes are configured by an administrative user and define the start / prefix of a hostname and append a unique number to end. The prefixes can then be attached as a default to a business group and / or consumed by blueprint components.
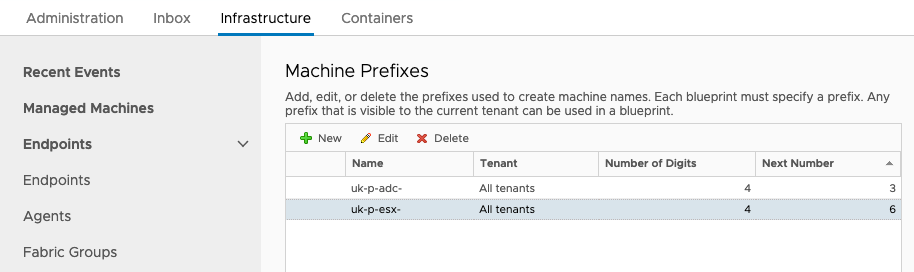
For my naming convention however, I'd need to create a large number of prefixes and / or dynamically set the Environment part of the name using an event subscription unless I want a lot of blueprints. If I'm going down that route, why not just call out to an external system and make that authoratative for unique hostnames. Plus, I don't want vRA 8.x to be reliant on vRA 7.x to provide hostnames so I need something external to vRA 7.x.
vRA 8.x
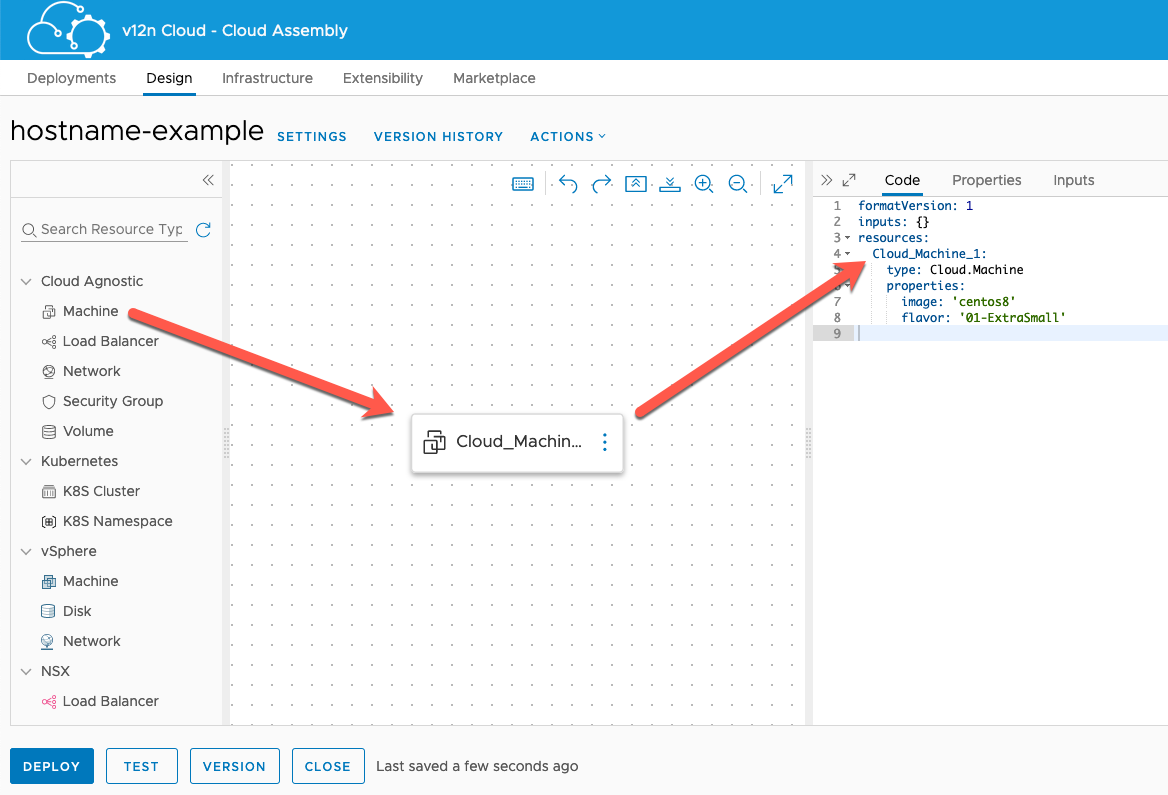
By default vRA 8.x creates unique names for VMs that are based on the name of the resource in the blueprint. This is appended with a unique string. In the simple example blueprint below, I dragged a cloud agnostic machine object in to the blueprint. The resource is automatically named "Cloud_Machine_1". (I could change that to anything that's unique in this blueprint.) When deployed, you get a machine named something like Cloud_Machine_1-mcm414-138897654620 provisioned in vCenter.
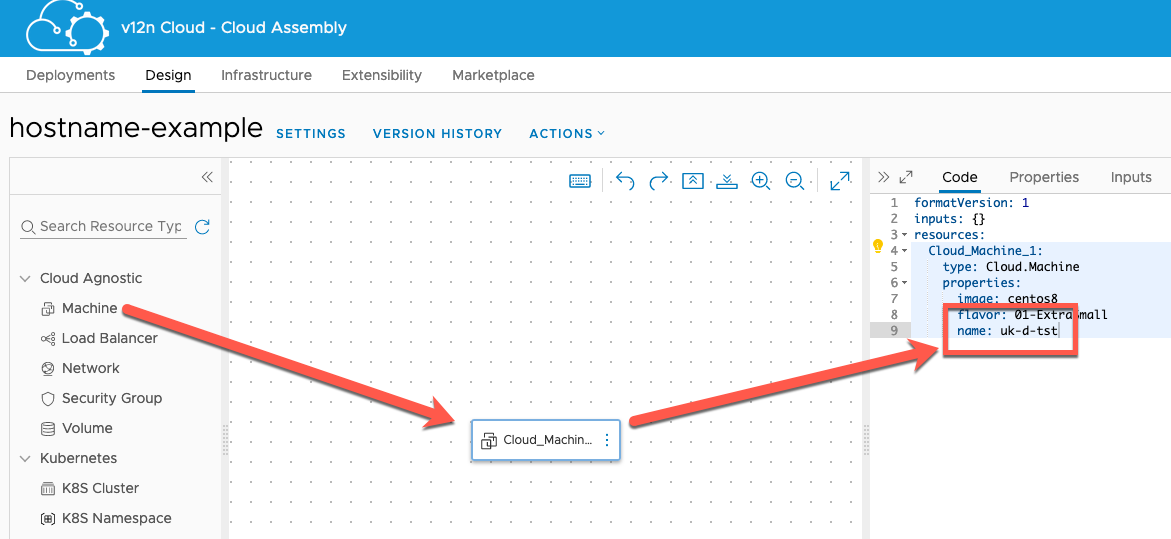
This default behaviour can be overidden using a name property on the resource. You still get a unique string appended to the end however. The resultant machine in this case was called uk-d-tst-mcm415-138897826567.
Another option exists at a Project level. In each Project within vRA 8.x there is an option to implement custom naming. You can either set a simple template that includes a unique number (e.g. "uk-d-tst-${####}") or you could incorporate input values or other properties. There's a wealth of possibilities that I'm not going to go in to now.
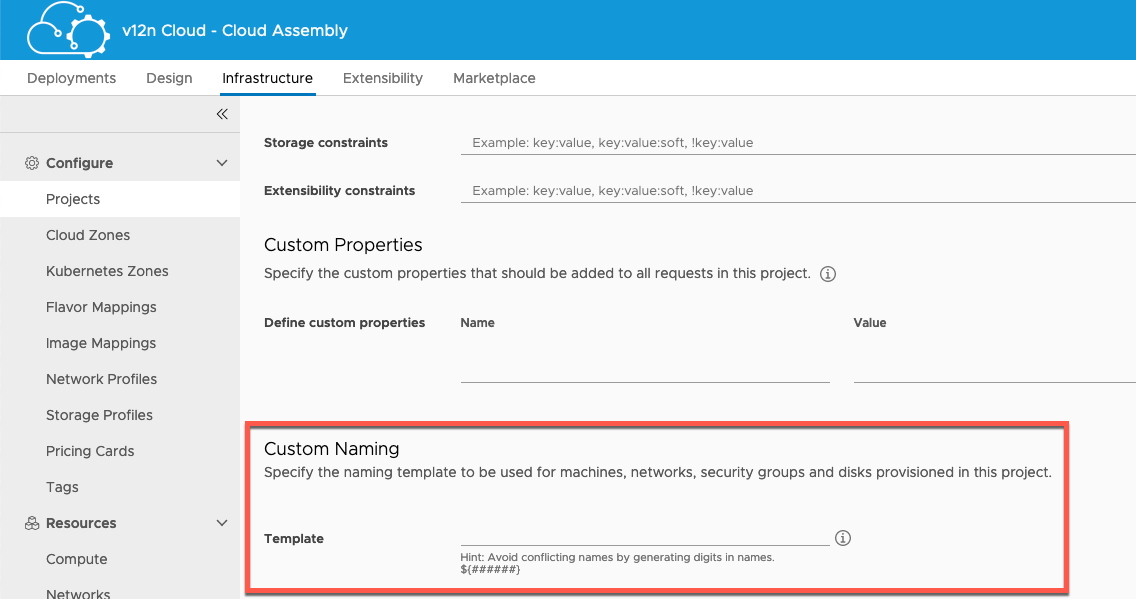
All of these options work well in their own right. However, the first two don't fit my convention and the third isn't automatically shared between different projects. And if I'm using vRA 7.x still, I don't want to start tying that to 8.x anymore than I want to tie 8.x to 7.x.
So what's the solution?
High-Level Overview
As I've already touched on, I needed something external to vRA 7.x and vRA 8.x to handle my naming functionality and have both versions consume names from it. My chosen approach was to create a standalone vRealize Orchestrator instance and use it to manage hostname allocation. I'd then add event subscription in 7.x and 8.x to requests the new name workflow from vRO and apply it. I think that a picture here would be appropriate.
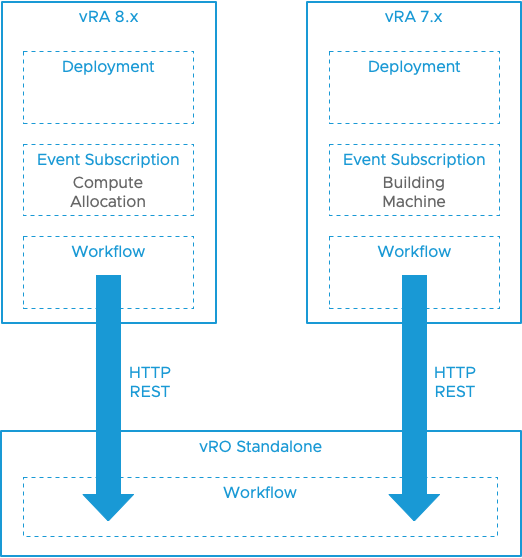
In vRA 8.x, we can create an event subscription that is triggered at the Compute Allocation stage and that is blocking. Like in vRA 7.x, we can configure a workflow to execute when this subscription is triggered. This workflow takes some information from the requested deployment and fires it in to a remote execution of the naming workflow in the standalone vRO instance. That remote workflow generates the hostname(s) and sets them as its output.
The workflow in vRA 8.x picks up the output from the remote execution and applies the returned name(s) to the deployment. (A similar process can be employed for vRA 7.x, but I won't cover it in any detail in this post.)
Now we know what the process looks like, let's build it!
Generating and Recording Unique Hostnames
Let's assume that we have deployed and configured a standalone vRO instance that is licensed and authenticated by vCenter. (For this first version I decided to go with vRO 7.6 as it has a smaller footprint than 8.x has.) We need a workflow that generates new, unique hostnames. As I mentioned, Mark already created that. I made some changes.
My first change was to swap the string that was used to record the unique number for each role to a number. I also put them all in a single Configuration Element called "hostnames":
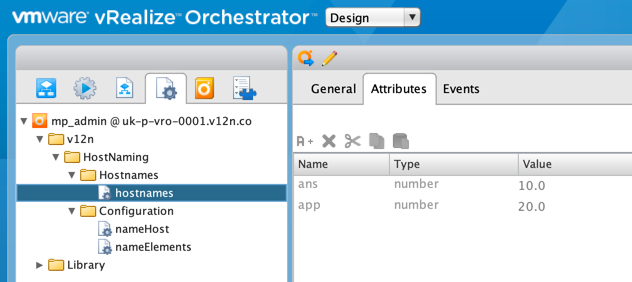
The next thing I wanted to do was make my naming convention configurable without having to make code changes. In the "nameElements" Configuration Element I placed the output format for hostnames, along with the case to be used and the name component that determines uniqueness (in my case it's the "role"):
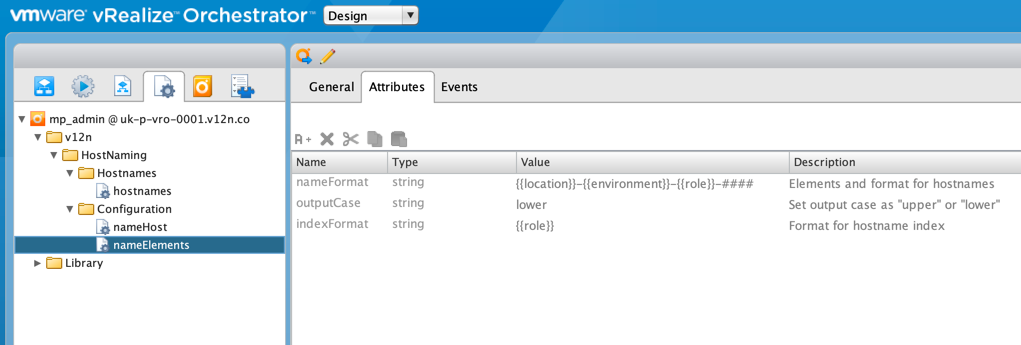
(Ignore the "nameHost" element for now. That's actually needed for the vRA side of things.)
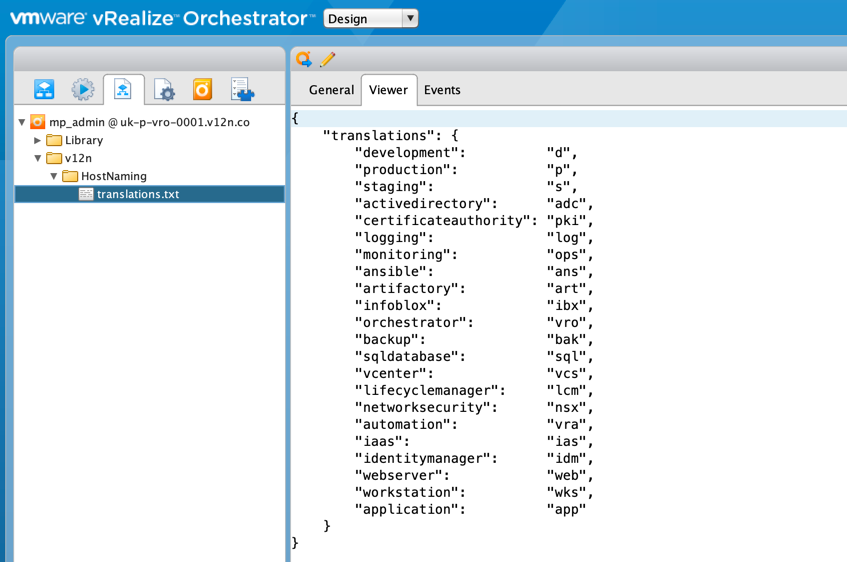
Next up, I wanted to enable some translations to take place. For example, I wanted the word "production" to be replaced by the letter "p", or the word "application" to be replaced by "app". That way I could easily add or change things and, more importantly, have slightly more friendly options displayed displayed in vRA that I pass directly through. I mean would you rather select "Ansible" as a server role or "ans"?
To achieve this I felt that the quickest way would be to pop the mappings in to a JSON construct and add it as a Resource Element:
Now for the workflow. It's just a single workflow and it has a single input, a string called "request". All of the attributes are mapped back to the various Configuration and Resource Elements detailed above. The steps to create and remove locks just uses Orchestrator's built-in locking system to make sure that the workflow never tries to produce multiple hostnames concurrently.
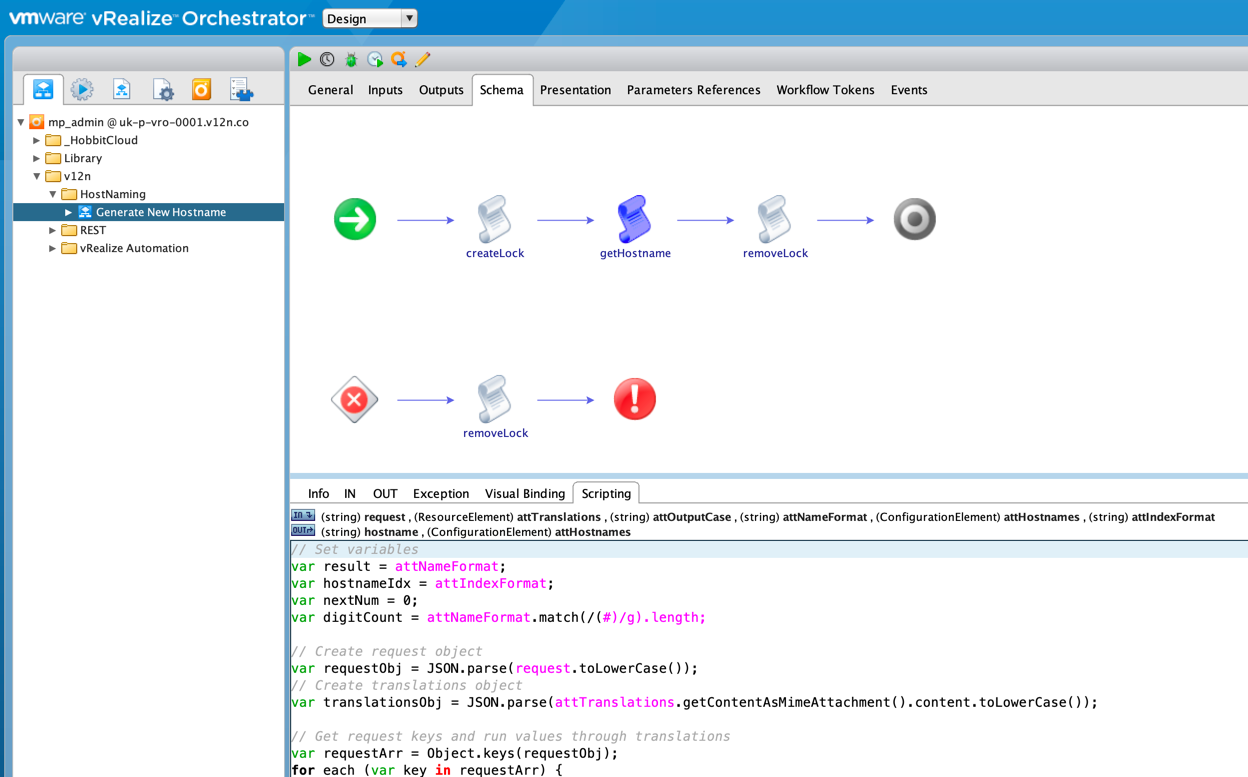
And here's the code in that scriptable task...
I won't step over it line-by-line, but in essence what happens is:
- The workflow input is provided as a JSON formatted string with my chosen properties in it. Those being "location", "environment" and "role". The first step is to parse the request in to an object.
- The translations JSON is then parsed in to an object too.
- Next, we step through the properties sent in the request and look for translation matches. If we find one we replace the relevant placeholder in the nameFormat template.
- Once complete, we use the indexFormat to get the next number or create a new entry and increment the number.
- The number is padded out to the number of didgts required and added to the hostname.
- Finally the case is processed and the hostname is set as the workflow's output.
It's not perfect, but it works! Now, as this is getting a tad long I'm going to finish here and post the rest tomorrow.