vRetreat London 2018 and Zerto Virtual Replication 6.0

I was lucky enough last year to be invited to the inaugural UK vRetreat, organised by fellow vExpert Patrick Redknap. If you've not encountered a vRetreat before, or are wondering what it is, it's an event with a small delegation of bloggers invited to pick apart some presentations by the event's sponsors.
![]()
![]()
Following on from Silverstone in 2017 I had assumed that I'd had my shot and that other bloggers would get their chance at the next event. Fast-foward to February 2018 and I again found myself sitting down with a number of quality vCommunity members to exchange stories and, most importantly for vRetreat, listen to some detailed presentations by a select delegation of IT vendors.

One key difference between the two events (I think that Barry Coombs and myself are the only two attendees of both events) was the venue and the “extra-curricular activity”. Instead of the Porsche driving experience from last year, we would all be entering the Crystal Maze. (Great fun, especially if you remember the TV game show, although the team I was on had two people carrying injuries and, to be honest, we sucked!)
The venue for the daytime, technical part of the day was familiar to me too from the numerous times that I've been to CloudCamp in London. Ominously named “The Crypt”, it is in fact a Church near Farringdon.
Back to the purpose of the vRetreat. Although I mentioned presentations before, the idea is that it starts out that way but, with a smaller audience, it gets a bit more interactive as the attendees ask lots of detailed questions that you might not get in a larger setting. On this particular occasion, we had the pleasure of hearing from Zerto and Cohesity. With the room divided between the two, I have the pleasure of covering Zerto.
In addition to Louise Eddy (who's emailed me and tweeted me a few times in the past, but who I had yet to meet until this event), Zerto was represented at vRetreat by Gijsbert Janssen van Doorn – a very charismatic chap from the Netherlands who can't say the word “ephemeral”. (I'm not being mean by the way, he'll freely admit that!) Zerto's focus at the moment is on their product Zerto Virtual Replication 6.0 and how they “Solve for Multi-Cloud”.
“Master of Disaster”
If you haven't encountered Zerto before, they've been around for a number of years now, having been founded in 2010. An earlier version of ZVR won “Best in Show” at the VMworld 2011 awards. (Incidentally, I have in my wardrobe, several iterations of the “Master of Disaster” t-shirt still. It's great for confusing non-tech savvy relatives.) The USP of their earlier software was to move data replication from the storage layer in to the hypervisor, making them a replication solution for all storage solutions in a virtual environment.

Of course, times have moved on (for most people at least), and many enterprises are not just looking at how to move data from production to DR to answer their availability requirements, they're looking at providing workload mobility, addressing other security concerns and also moving workloads not just between different datacenters, but between different clouds. It is in to these new areas that Zerto have taken their product with Zero Virtual Replication 6.0. In their own words:
“Single platform for continuous availability, data protection and workload mobility to, from, or between multiple clouds.”
The first keyword keyword there is “platform”. From their earlier product versions, that focussed on moving data from, for example, a vCenter in one location to another, they're now focussed on solving that challenge between different clouds, both private and public. And all of this without having to install an agent in every workload. I think it's true to say that Zerto have more of a platform than a product now. It makes me wonder if a change of name might be worthwhile to better position their offering?
Zerto and AWS
The second, and most important, point there is “multiple clouds”. What does that mean? ZVR has been able to replicate workloads in to AWS since version 4.0 in 2015 (workloads should ideally have AWS compatible drivers pre-installed). Only recently however has “failback” from AWS been possible though.
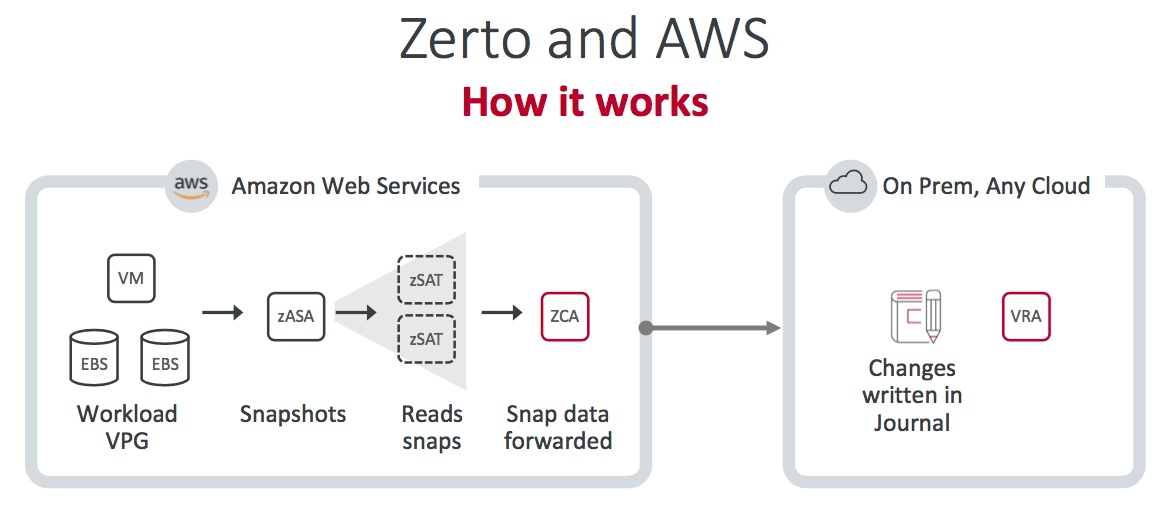
(Note: Many of the Zerto objects (zASA, zSAT etc) are deployed and managed automatically by ZVR when replication out is configured.)
It should certainly be noted however that replicating out from AWS is going to incur charges from AWS for the data transferred. Here, ZVR comes in to its own by minimising the amount of data sent. Although I imagine that it might not be cheap to mass-move a large number of workloads! AWS also lacks a Changed Block Tracking (CBT) API at present that Azure has already, which is one of the reasons why the offering differs very slightly and represented a bit more of an engineering challenge.
Zerto and Azure
For Azure, things are technically a little simpler. Politics can play a part in some regions (Germany won't permit VPN connections to other regions for instance) but on the whole the process is simple, at least from the customer perspective!
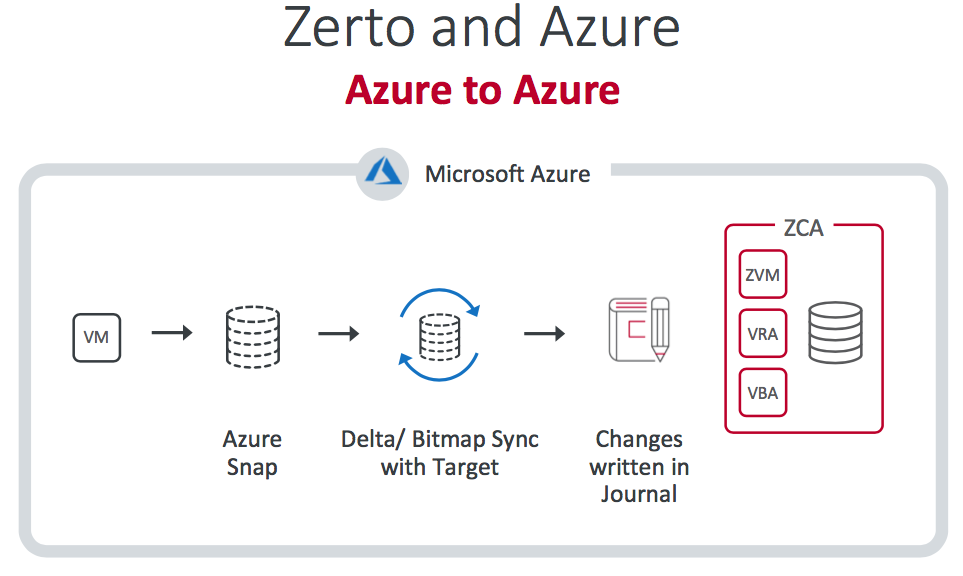
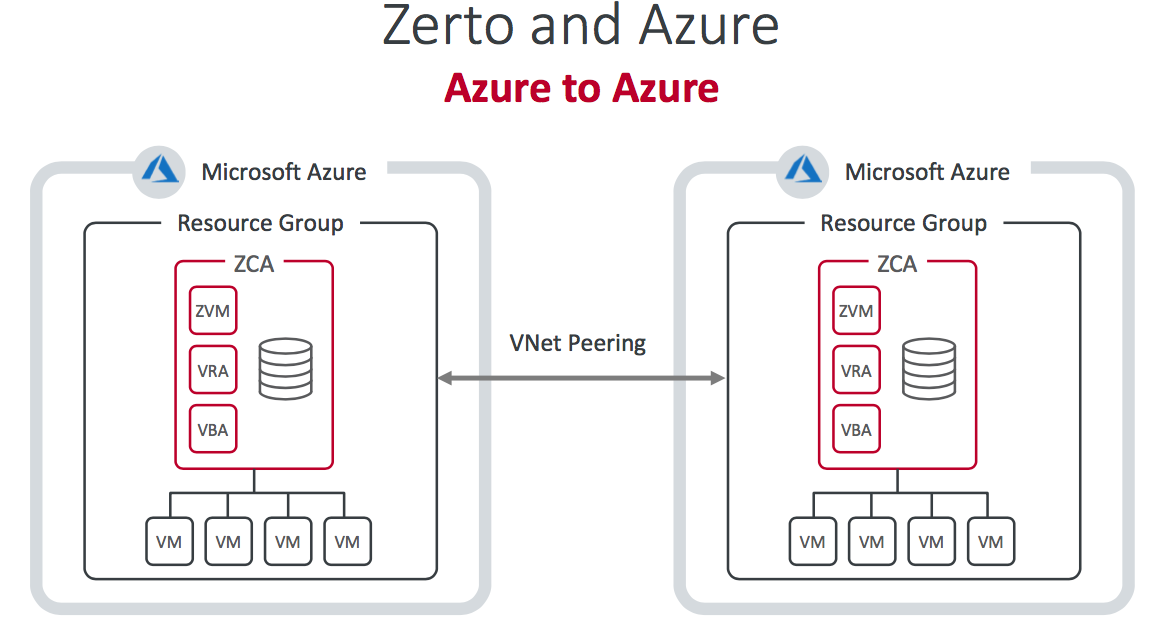
ZVR 6.0 also works with IBM Cloud and, if you take advantage of their DRaaS service it actually leverages Zerto!
What you end up with is the ability to replicate workloads from and to several on-premise or public cloud platforms. As you might imagine, there are a large number of possible use-cases for this:
- Datacenter migrations
- DR
- Leveraging cost efficiencies in different locations and platforms
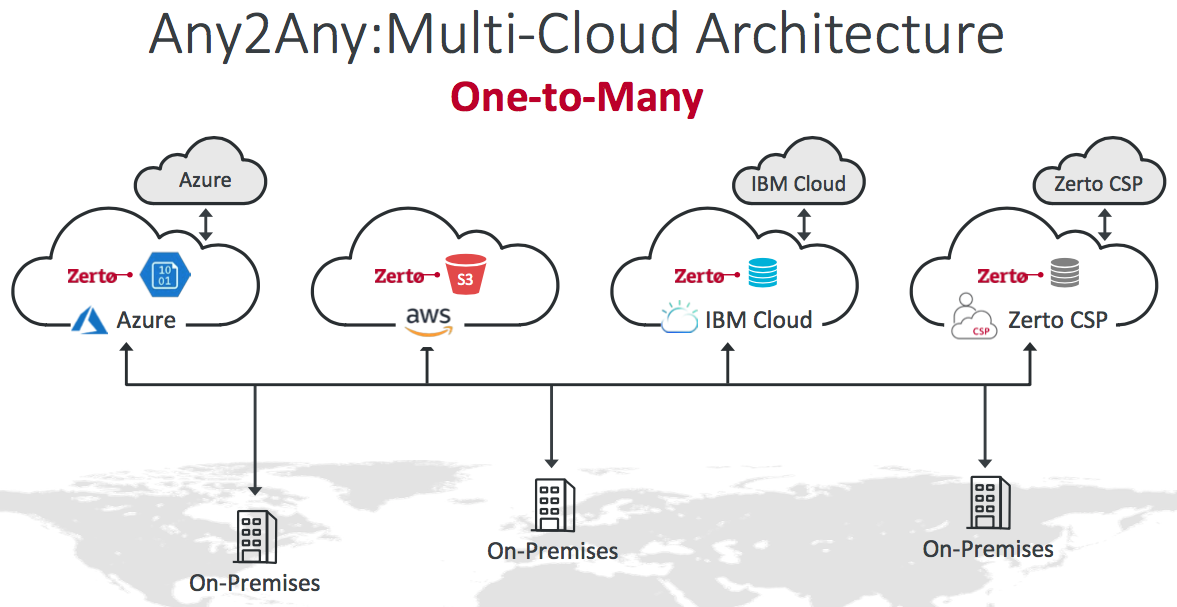
As he presented this particular slide, Gijsbert reinforced the “One-to-Many” statement with us to highlight that ZVR could replicate the same workloads to multiple locations at once (not from AWS at present though). That's pretty powerful if you want to maintain multiple redundant copies of a workload.
Zerto Analytics
Of course, if you have a presence in one or more clouds, how do you know which one you should be running in and how do you know how much it will cost to move the workload there? There were a few questions asked in this area, and Zerto has some of the answers baked in to the platform. As you might imagine, with that much data moving from A to B, B to A or even B to C etc, the need for decent analytics is important.
ZVR includes an analytics engine that aggregates data from whichever platforms it is running in and dashboards to provide summary of network activity:
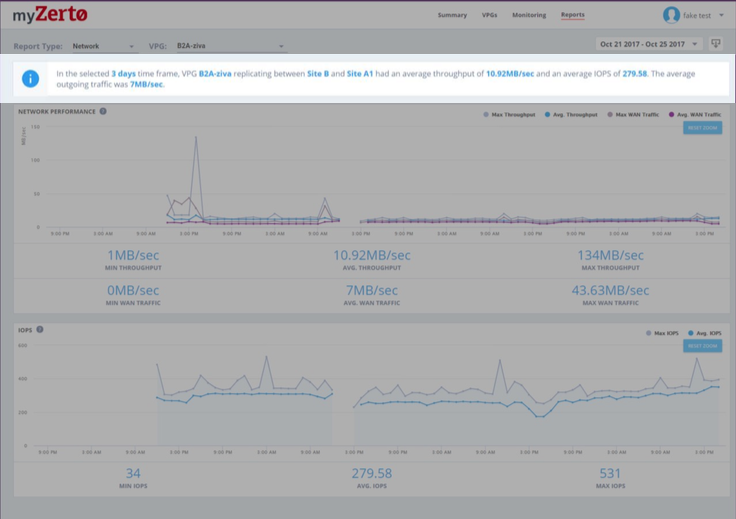
Network performance history:
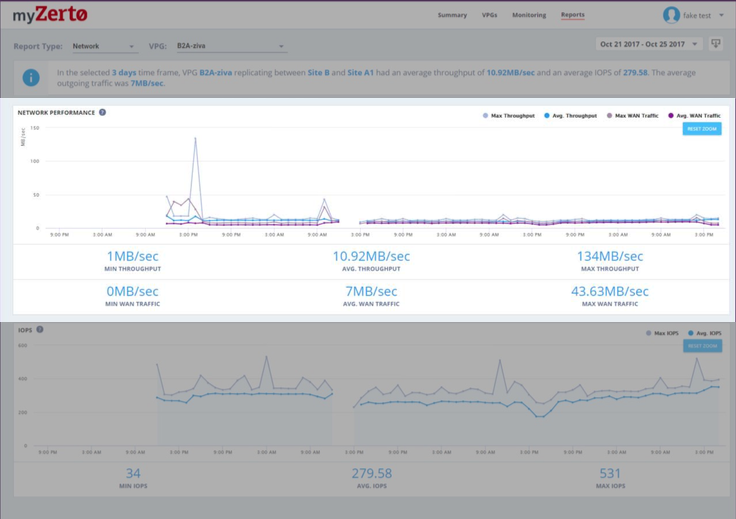 IOPs history:
IOPs history:
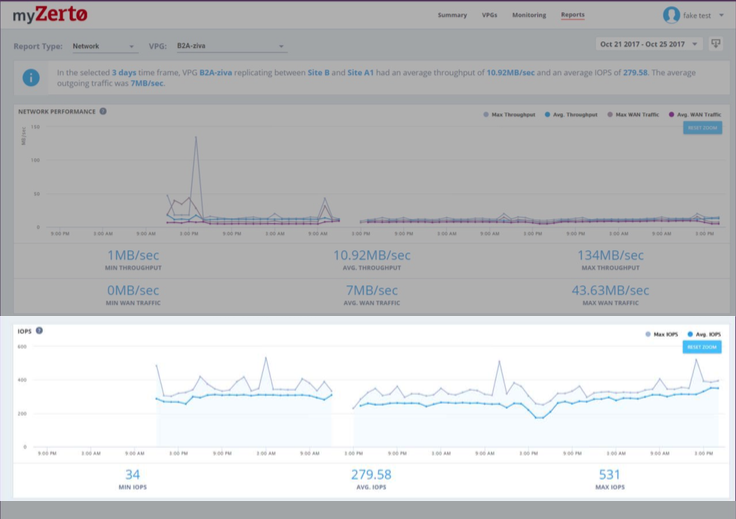
and more…
Journal File Level Recovery
Hearing about it all was quite exhausting. But there is more to the platform under the hood as well a rather nifty feature that is born from the way in which ZVR replicates workloads. Because it replicates only changes to workloads over time (to save bandwidth and provide good performance), a journal of replication changes can be kept providing a mechanism for rapid file recovery.

A great feature, but possibly not a complete substitute for a reliable backup of your critical data.
Zerto have come a long way from their beginnings and it's great to see the broad coverage and capabilities that their platform has now and has coming in future releases. I've recommended them to customers in the past and I know that they've been very happy. Just one piece of feedback for Zerto, they might need a new slogan for their t-shirts. I think they do much more than manage disasters now!