Migrating from Wordpress to Hugo Part 1: Overview

I originally drafted this in June 2018. Following on from Sam McGeown's recent migration to Hugo, I thought I'd finally publish this in case it's useful for anyone rather than sitting on it until I complete the process!
What, When and Why?
I've been blogging using WordPress for about 10 years. In recent months I've seen several respected bloggers make the move to Hugo and it has inspired me to do the same. You might ask “Why?”, and I have a few reasons:
- For starters, I want to improve my skills and knowledge in certain areas of cloud technology. The LAMP (Linux / Apache / MySQL / PHP) stack that WordPress sits on isn't exactly revolutionary.
- Next, I want to simplify the site itself and reduce the chances of it being hacked.
- Finally, the most important reason, because I can!
This series of posts will document my journey.
The Starting Point
WordPress is a great solution, don't get me wrong about that. I've been using it since 2008 to host my blog through its various iterations. During that time WordPress has evolved into quite a mature solution, with a rich ecosystem of theme developers and plugins. It just works and you don't have to have ninja skills to get your ideas shared with the world. However, every time I login to my self-hosted WordPress installation, there's a dearth of updates waiting for me to apply them. From time-to-time you get incompatibilities come up and you have to swap out one plugin for another. Also, as the database grows it can become more of a challenge to back up the site or migrate it to a new hosting provider – something I do from time to time to keep the cost of running it down.
As it stands, the starting point looks something like this when it comes to retrieving content from michaelpoore.com (not trying to teach anyone to suck eggs here, I just fancied drawing a diagram – it also helps compare with the finishing point below):
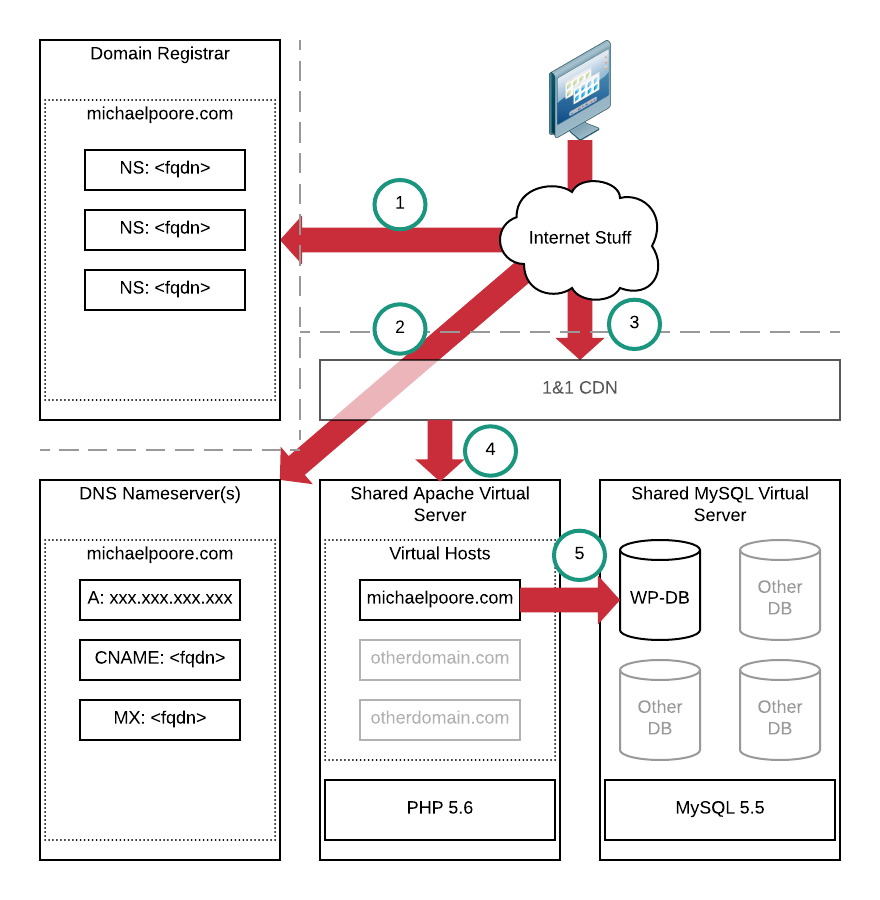
- Web browser requests a page from michaelpoore.com and a DNS query is triggered that results in the nameservers for the domain being queried.
- The nameservers for michaelpoore.com (hosted by 1&1) are queried for the website IP address.
- A connection is made to the 1&1 CDN (Content Delivery Network) for the requested page. That page may be served directly by the CDN or the backend Apache server may have to provide the content.
- Assuming at least part of the content is not cached by the CDN, the Apache webserver receives the request and various PHP scripts are executed to render the page content. Combined with other elements such as images and javascript, the content is returned back to the requesting web browser.
- The aforementioned PHP scripts will make numerous queries to the MySQL database.
Now, unless you're adding lots of dynamic content (which I'm not), and unless the CDN is caching significant portions of the returned content (which I don't know), then there's a lot going on each time a page is requested. Also, each plugin I add or the WordPress installation in general just represents a greater attack surface. I'm not that arrogant as to believe that anyone would want to hack my blog, but you never know.
Of course, I could migrate from a self-hosted solution to a hosted WordPress site and take away some of the issues that I have (such as applying updates to WordPress and the infrastructure (PHP and MySQL – which I have to update via the 1&1 control panel from time-to-time). I'm all for using such solutions typically, but it seems too easy 🙂
The Finishing Point
Hugo isn't exactly a webserver. It's actually a static site generator. It creates a structure of flat HTML files that can be hosted somewhere. As there's no dynamic content, the pages are very easy to cache. In terms of my finishing point, much of the process looks the same as above:
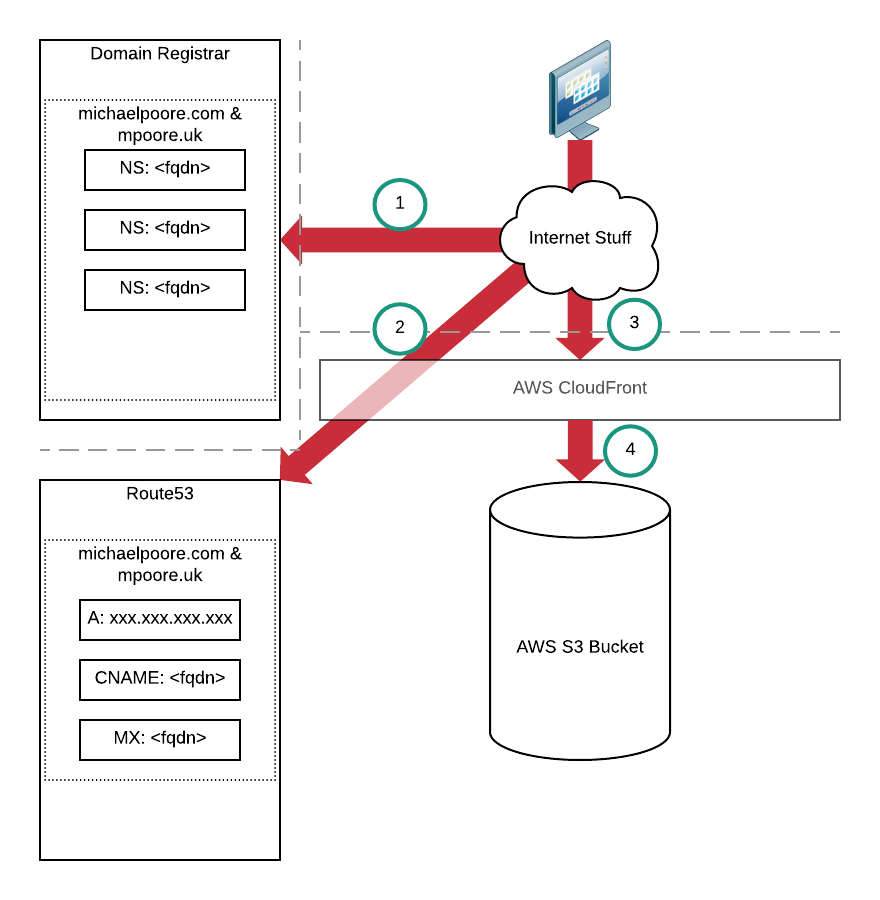
(One key difference is that I'm introducing another domain name in to the mix. This is partly to help with the migration process, but also because I'll end up redirecting one of them to the other and I wanted a domain name that matched my twitter handle.)
- Web browser requests a page from michaelpoore.com (or mpoore.uk) and a DNS query is triggered that results in the nameservers for the domain being queried.
- The nameservers for michaelpoore.com (hosted by AWS Route53) are queried for the website IP address.
- A connection is made to the AWS CloudFront CDN (I could also use CloudFlare) for the requested page. That page will likely be served directly by the CDN.
- Assuming that the page content cache has expired or perhaps has never been created, the HTML file will be served directly from the AWS S3 bucket.
That should be so much quicker. But let's talk briefly about how the HTML files get in to S3 in the first place. That is where Hugo comes in as well as a few more pieces that I'll cover in a later post.
The Journey
So now that I've mapped out the starting point and the finishing point, we've got the makings of a journey. Let's get started!